chapter 3 Inverted File Index¶
基本概念¶
definition
倒排索引的引入和定义:从两个naive的想法出发,其一是遍历搜索,这样太耗时间;其二是稀疏矩阵,这样存储比较浪费空间。所以我们改进为链表存储,这就是倒排索引。注意在倒排索引里面我们保存单词的出现次数是因为当多个单词同时搜索时,从出现最少的词入手搜索会更快。
| 遍历搜索 | 稀疏矩阵 | 倒排索引 |
|---|---|---|
 |
 |
 |
Example
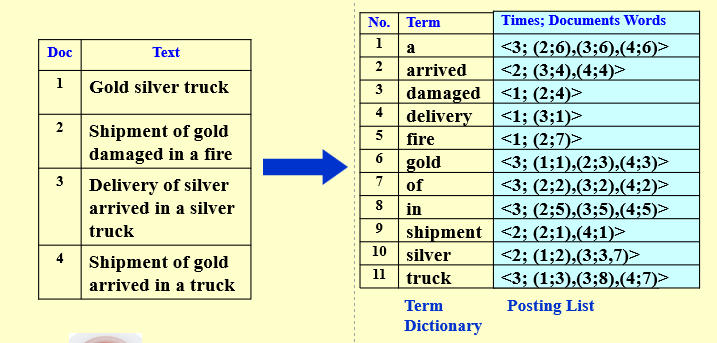
为什么叫倒排索引
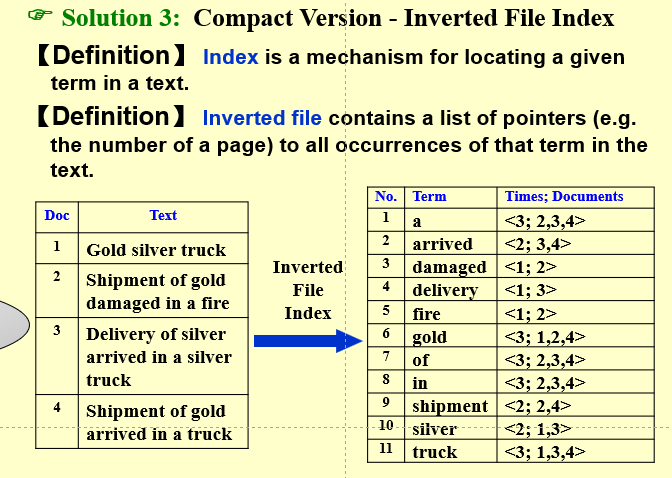
倒排索引源于实际应用中需要根据属性的值来查找记录。这种索引表中的每一项都包括一个属性值和具有该属性值的各记录的地址。由于不是由记录来确定属性值,而是由属性值来确定记录的位置,因而称为倒排索引(inverted index)。带有倒排索引的文件我们称为倒排索引文件,简称倒排文件(inverted file)
构建¶
- 如何构建倒排索引:逐个词语读入插入构建。其中会有很多问题,例如分词,stemming,stop words等,还有通过搜索树或 hash 访问等;除此之外还有存储上的考量,因为内存不够需要存储到外存,外存可以分布式存储(两种方式),然后还有更新时可以用 cache 等改进存储效率。
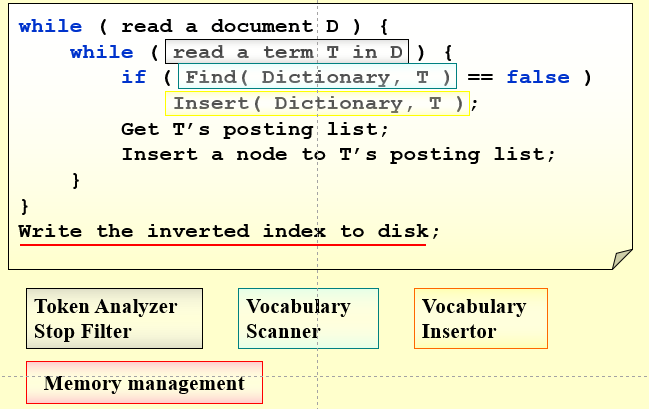
Dynamic indexing¶

Distributed indexing¶

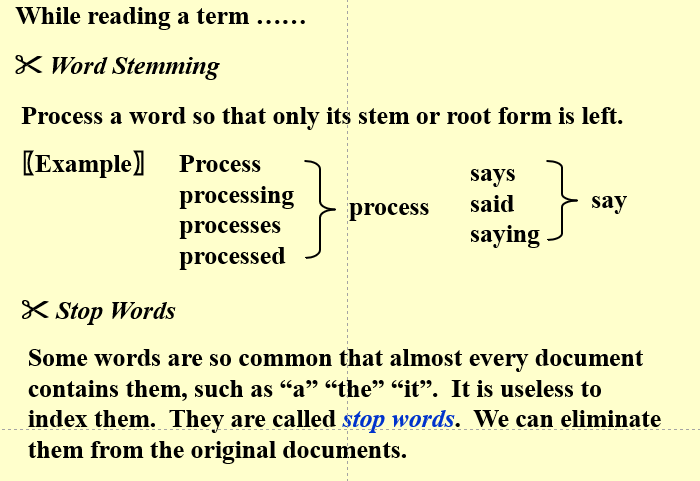
分词器¶
Thresholding(检索阈值)¶
- Document: only retrieve the top x documents where the documents are ranked by weight
- Not feasible for Boolean queries
- Can miss some relevant documents due to truncation
- Query: Sort the query terms by their frequency in ascending order; search according to only some percentage of the original query terms

Compression¶

如何评价检索系统¶
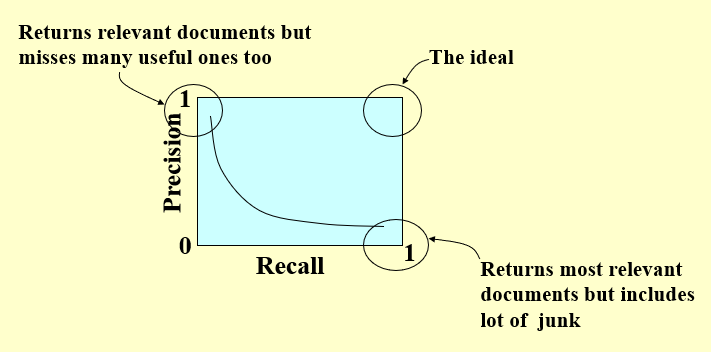
- 搜索引擎的评价:区分 Data Retrieval 和 Information Retrieval,了解准确率和召回率两个重要0的衡量参数(与此对应还有假阳性和假阴性),其中阈值的设置是重要的影响因素

- Relevance measurement requires 3 elements:
- A benchmark document collection
- A benchmark suite of queries
- A binary assessment of either Relevant or Irrelevant for each query-doc pair
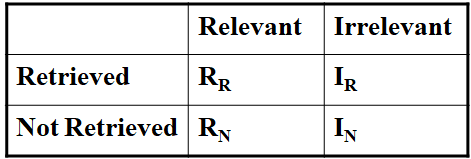
- Precision \(P = R_R / (R_R + I_R)\)
- Recall \(R = R_R / (R_R + R_N)\)